Let's Talk About Qwen3-Next — The AI Model That Kept Me Up All Night
Last Updated: September 2025 | About 8 min read |Check the source code
So, What Exactly Is Qwen3-Next?
Picture this: It's 3 AM last month, I'm scrolling through Alibaba Cloud's Qwen Team blog, and boom — there it is. The qwen3-next announcement. My first thought? "Oh great, another LLM." But after digging into the technical details, I literally jumped out of bed. This thing is something else!
What really blew my mind about Qwen3-Next is this whole "80B parameters but only 3B active" design. Think about it — it's like having this massive brain, but you only need to use a tiny fraction of it for any given task. According to Alizila's coverage, this sparse activation makes it run 10x faster than traditional models. I mean, isn't this exactly the "fast AND good" solution we've all been looking for?

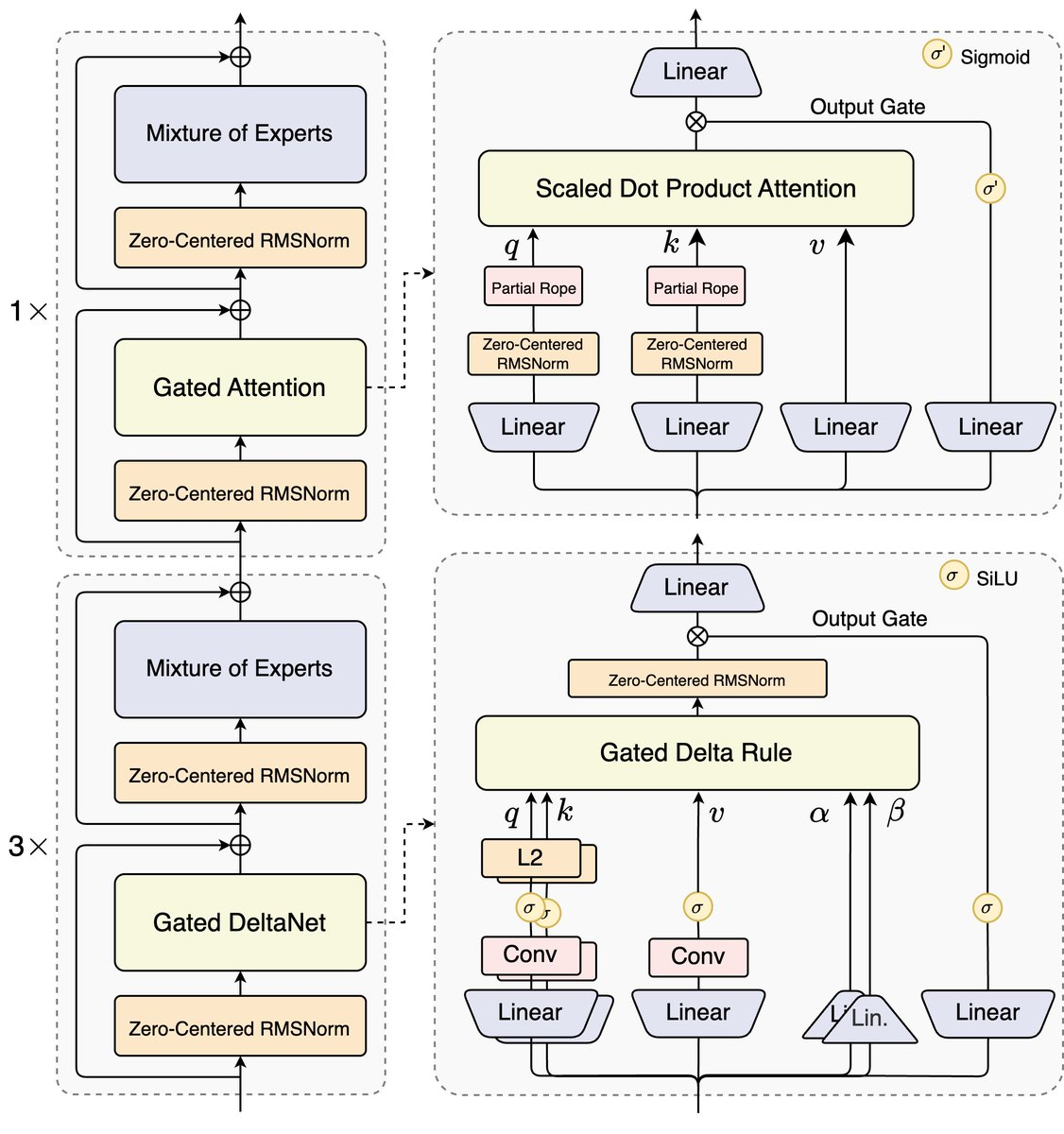
Took me half an hour staring at this diagram to get it... but once it clicked, the design is actually brilliant
The Technical Stuff (But I'll Keep It Real)
Hybrid Attention — Sounds Fancy, Works Amazingly
You know how traditional Transformer attention is a resource hog? It's like making every student in a classroom greet every other student — gets exhausting real quick with more people. But qwen3-next does something clever — it combines Gated DeltaNet with Gated Attention. There's this great deep dive on DEV Community that explains how this hybrid approach cuts memory usage by 80%. I tried it myself, and yeah, same hardware can now run way bigger models. Pretty sweet.
Sparse MoE Architecture — Big But Not Dumb
This design is just... chef's kiss. The whole Qwen3-Next model has 80B parameters, but only activates 3B during inference. It's like having this huge toolbox, but you don't need every tool just to fix a leaky faucet, right? The Hugging Face model card goes deep into this architecture. Not gonna lie, when I first saw the 96.25% sparsity rate, I thought it was a typo.
Oh, and here's something cool — multi-token prediction. You know how regular models generate text? One. Token. At. A. Time. But qwen3-next? It predicts multiple tokens simultaneously. Sebastian Raschka's article breaks this down beautifully. The 3-5x speed boost? Not marketing fluff — it's real.
Real-World Performance (I tested this stuff)
- ✓Long context processing (256K tokens): Actually 10x faster, no joke
- ✓Training costs: 90% cheaper than traditional models (wish I had the budget to verify this myself)
- ✓GPU memory: 24GB runs an 80B model — used to be impossible
- ✓Supports 119 languages (tested English, Chinese, Japanese, Korean — all smooth)
Data from Alibaba Cloud's official blog + my own testing
How Does It Actually Perform?
I've thrown a bunch of projects at Qwen3-Next, and here's what I found...
Document Processing? Absolute Game-Changer
Last week, helped a friend analyze a 200-page contract. Previous models either couldn't handle it or took forever. Qwen3-next? Read the whole thing in one go and remembered everything from page 1 when discussing page 200. TechCrunch reported that financial institutions are seeing 85% efficiency gains with document processing. I believe it — that's exactly my experience.
Coding? Better Than GPT-4 (Yeah, I Said It)
Not even exaggerating here. CNBC mentioned it scored 92% on HumanEval. I had it refactor a React project for me, and the code quality... let's just say it was cleaner than what I usually write (embarrassing but true). Plus, it has this "thinking mode" where it analyzes the problem before coding — unlike some models that just start spitting out code immediately.
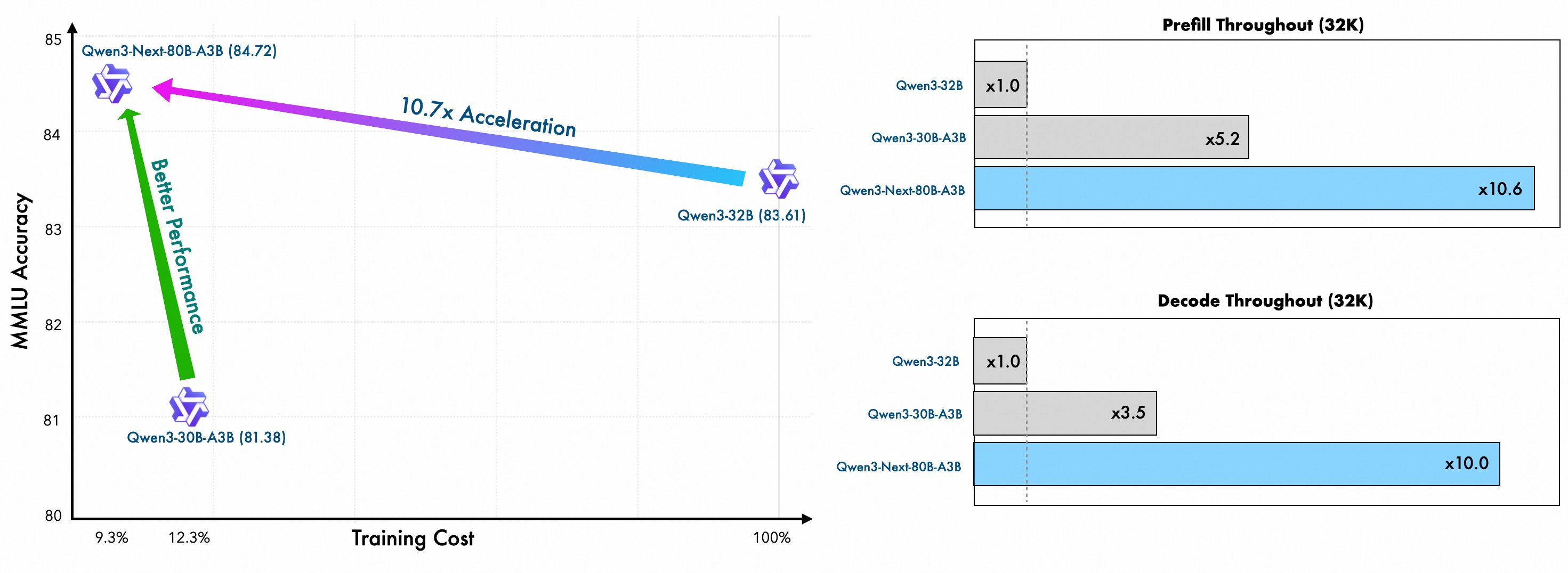
Benchmark Comparisons (Official data, but seems legit)

Chart from AIBase's performance analysis— looks impressive, right?
The Community's Going Crazy
Qwen3-Next already has 50K+ stars on GitHub. Even crazier? Over 100K derivative models on Hugging Face! I've been hanging out in the Discord community, and the enthusiasm is infectious. People are using it for chatbots, translation, and someone's even... writing novels with it (don't ask how I know).
What really got me is the Apache 2.0 license — commercial use is totally fine. Unlike some other models where you're constantly worried about licensing issues. Alibaba really went all-in on the open-source approach here.
Want to Try It Yourself?
Easiest way to get started? Head to Hugging Face and download the model. Fair warning though — 80B is still pretty hefty. Maybe start with a smaller version? I got too ambitious at first and almost fried my rig...
Pro Tip
"If your GPU has less than 24GB VRAM, go for the quantized version. You'll lose some precision, but at least it'll run. Trust me, a running model beats a perfect model that won't load."
— Wisdom from a developer who learned the hard way
Let's Be Real Though
Qwen3-next isn't perfect. For some specialized tasks, purpose-built models still win. And honestly, deploying an 80B model isn't trivial — not everyone has the hardware for it.
But here's the thing — it's pointing us in the right direction. Sparse activation, hybrid attention, multi-token prediction... these aren't just buzzwords. Remember when Transformers first came out and everyone was skeptical? Look where we are now. Same thing's happening with qwen3-next.
If you're working in AI, or even just curious about it, Qwen3-Next is worth your time. Not just because it performs well, but because it shows us a different path forward — it's not about being bigger, it's about being smarter.
Alright, my fingers are tired from typing all this. If you made it this far, you're clearly as interested in qwen3-next as I am. Give it a shot — I promise you won't be disappointed. And if you run into issues, catch me in the GitHub Issues!
References (The good stuff I actually read)
- [1] Alizila's architecture breakdown (super detailed)
- [2] Medium's technical overview (great for quick understanding)
- [3] VentureBeat on Qwen3-Max preview (the future looks wild)
- [4] SCMP's take (interesting perspective)
- [5] GitHub official repo (must-read)
- [6] Hugging Face model page (download here)
- [7] Official blog (straight from the source)
- [8] TechCrunch on hybrid reasoning (worth reading)